
취약점 도메인 쿼리 속도 개선 연구
목차
Vulnerability 리스트를 가져올때 호출되는 mybatis Mapper
문제점
취약성 탭에서 검색을 할때 검색 시간이 너무 긴 issue가 있었습니다.
빈칸으로 검색한 경우 foslight는 쿼리에 필터를 적용하지 않습니다(전체 검색) 이때 검색시간이 20초이상으로 길어지게 되고 결국 timeout이 발생하고 맙니다.
그래서 저는 이문제의 해결방안을 찾아보기로 했습니다.
Vulnerability 리스트를 가져올때 호출되는 mybatis Mapper
public HashMap<String, Object> getVulnerabilityList(Vulnerability vulnerability, boolean exportFlag) {
...
...
int records = vulnerabilityMapper.selectVulnerabilityTotalCount(vulnerability);
vulnerability.setTotListSize(records);
List<Vulnerability> list = null;
if(exportFlag) {
list = vulnerabilityMapper.selectVulnerabilityExportList(vulnerability);
}else {
list = vulnerabilityMapper.selectVulnerabilityList(vulnerability);
}
map.put("page", vulnerability.getCurPage());
map.put("total", vulnerability.getTotBlockSize());
map.put("records", records);
map.put("rows", list);
return map;
}
vulnerabilityMapper.selectVulnerabilityTotalCount : 취약점의 갯수를 셉니다.
vulnerabilityMapper.selectVulnerabilityList : 취약점의 리스트를 가져옵니다.
이 두가지 과정을 거쳐서 데이터를 제공하게 됩니다.
병목이 일어나는 지점
vulnerabilityMapper.selectVulnerabilityList
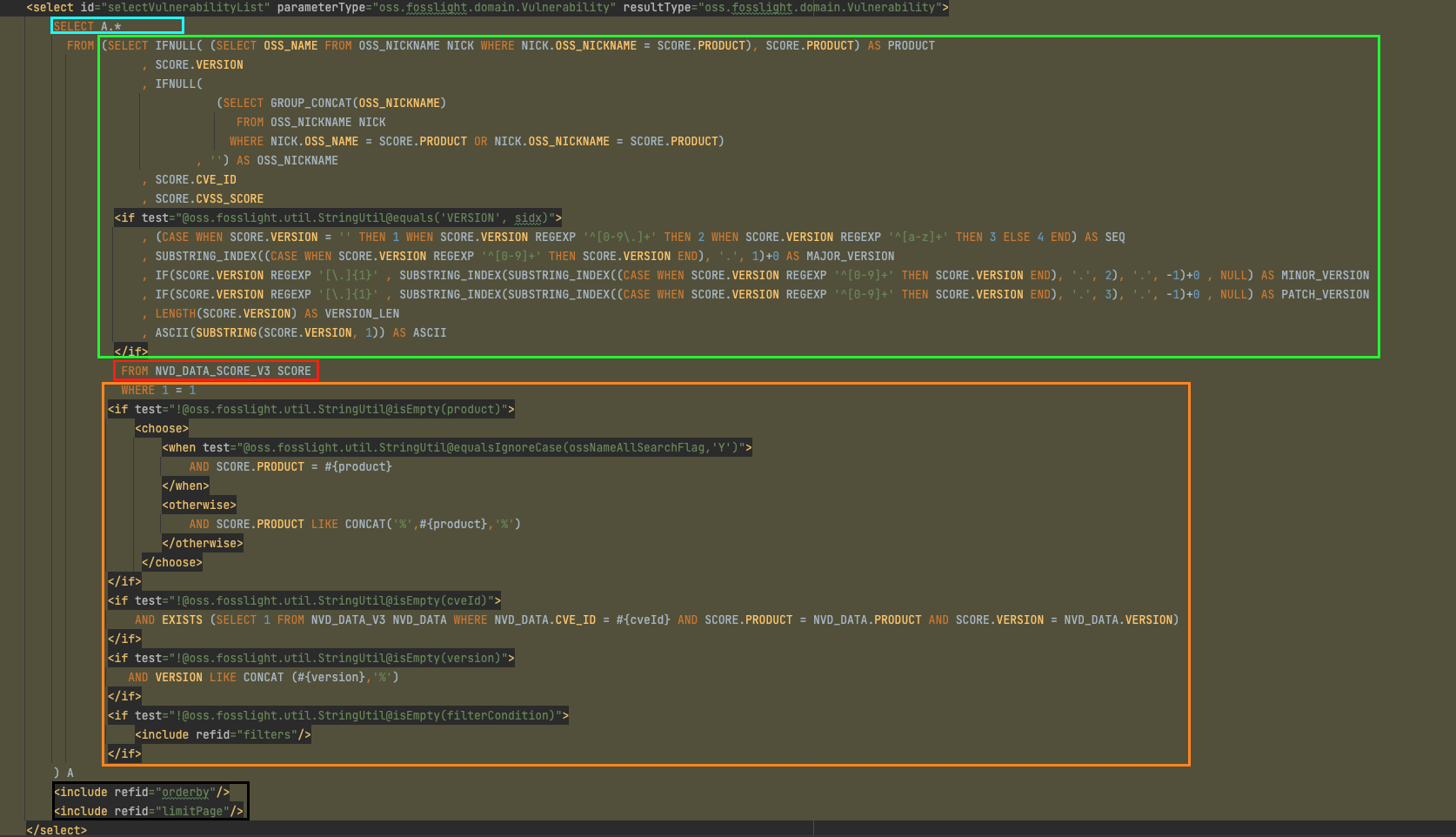
빨간색 → 주황색 → 연두색 → 하늘색 → 검은색 으로 실행됩니다.
정렬을 진행하고, 페이지를 가져오는 검정색 (limitpage) 블록을 맨마지막에 실행하는것 문제가 될수 있다고 생각합니다.
연두색 블록에서 NVD_DATA_SCORE_V3 와 OSS_NICKNAME과 서브쿼리를 진행합니다. 이때, 한페이지의 데이터의 갯수는 15, 30, 50 개 임에도 불구하고 NVD_DATA_SCORE_V3 전체 튜플 대상으로 OSS_NICKNAME 와 함께 서브쿼리가 진행됩니다.
NVD_DATA_SCORE_V3 튜플의 갯수를 N, OSS_NICKNAME 튜플의 갯수를 M 이라고 하면 연산시 최악의 시간복잡도는 O(N*M) 이 됩니다.
NVD_DATA_SCORE_V3 는 특성상 데이터의 수가 많으므로 응답시간이 느려질수 있습니다.
생각해본 해결책들
첫번째 방법 (쿼리 튜닝)
- 페이지의 행갯수만큼만 우선
NVD_DATA_SCORE_V3에서 가져옵니다. - 페이지에 대해서만 OSS_NICKNAME과 서브쿼리 을 하도록 구현합니다.
- O(N*M) 에서 N의 크기를 페이지의 크기(15, 30, 50) 만큼 줄일수 있습니다.
- 로딩시간을 강력하게 줄일수 있지만, oss_nickname을 사용한 정렬기능을 사용할수 없는 단점이 있습니다.
개선된 쿼리는 제 풀리퀘스트 에서 보실수 있습니다.
두번째 방법 (인덱스 생성)
# Welcome to the MariaDB monitor. Commands end with ; or \g.
# Your MariaDB connection id is 3
# Server version: 10.6.4-MariaDB Homebrew
# fosslight 데이터베이스 선택
use fosslight;
# OSS_NICKNAME 테이블의 OSS_NAME, OSS_NICKNAME 컬럼에 인덱스 생성
CREATE INDEX oss_name_index ON OSS_NICKNAME ( OSS_NAME );
CREATE INDEX oss_nickname_index ON OSS_NICKNAME ( OSS_NICKNAME );
# 생성된 인덱스 및 카디널리티 체크
# mysql관점에서의 카디널리티 = 중복을 제외한 유일한 데이터값의 수
SHOW INDEX FROM OSS_NICKNAME;
+--------------+------------+--------------------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Ignored |
+--------------+------------+--------------------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| oss_nickname | 0 | PRIMARY | 1 | OSS_NAME | A | 44 | NULL | NULL | | BTREE | | | NO |
| oss_nickname | 0 | PRIMARY | 2 | OSS_NICKNAME | A | 88 | NULL | NULL | | BTREE | | | NO |
| oss_nickname | 1 | oss_name_index | 1 | OSS_NAME | A | 44 | NULL | NULL | | BTREE | | | NO |
| oss_nickname | 1 | oss_nickname_index | 1 | OSS_NICKNAME | A | 88 | NULL | NULL | | BTREE | | | NO |
+--------------+------------+--------------------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
# 인덱스 삭제
ALTER TABLE OSS_NICKNAME DROP INDEX oss_name_index;
ALTER TABLE OSS_NICKNAME DROP INDEX oss_nickname_index;
- select시 서브쿼리에 사용되는
OSS_NICKNAME테이블의 두컬럼인OSS_NAME,OSS_NICKNAME에 index를 생성합니다. 조건검사시OSS_NICKNAME을 풀스캔하지 않아도 되므로, O(N*M) 에서 M의 값을 줄일수 있습니다. - 기존의 코드를 최대한 지킬수 있고, 적용이 빠른장점이 있습니다. 인덱스 생성만으로 시간을 첫번째방법만큼의 최적화효과를 얻을수 있었습니다.
- OSS 신규 생성 및 삭제시 인덱스 갱신을 위한 작업이 진행되어 약간의 성능저하가 발생할수 있습니다.
- 카디널리티가 낮으면 인덱스의 성능이 떨어질수 있습니다.
비교
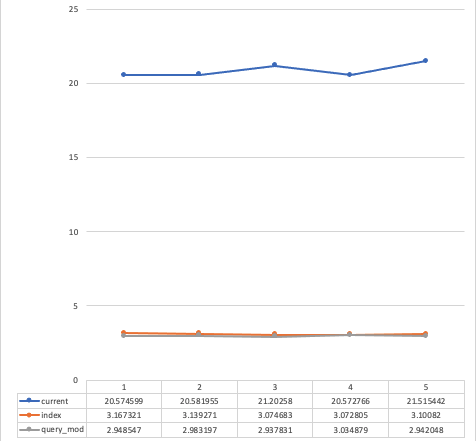
쿼리를 고치거나, 인덱스를 생성했을때 비약적으로 향상된 조회 쿼리 성능을 확인할수 있었습니다.
결론
가능하면 첫번째 방법을 사용하여 쿼리를 고치는것이 좋아보입니다.
하지만 기존의 서비스의 기능에 영향이 갈수 있으므로, 인덱스 생성을 먼저 시도해보는것도 좋은 방법이라고 생각합니다.
Leave a comment